Zeitreihen in Influxdb 2.x ändern

Zu Beginn des neuen Jahres ist es spannend, Sensorenwerte des letzten Jahres zu analysieren. Dabei fiel mir ein Fehler bei einigen Zeitreihen auf, in denen zu bestimmten Zeitpunkten Sprünge vorhanden sind. So ein Sprung tritt beispielsweise auf, wenn ich Zählerstände protokolliere, die zwischenzeitlich durch einen Reset oder Stromausfall des Sensors wieder bei Null beginnen. Für weitere Auswertungen führt das beispielsweise bei Differenzfunktionen zu fehlerhaften Berechnungen. Daher möchte ich diese Daten dauerhaft in influxdb korrigieren. Die folgende Vorgehensweise kann unabhängig von meinem Beispiel verwendet werden und zeigt die Korrektur durch einfache Nutzung der Flux-Sprache von InfluxDB 2.x auf.
Lösungsansatz
In meinem Beispiel habe ich Zählerstände eines Balkonkraftwerkes gespeichert. Diese erfasse ich mit einem einem eigenen Sensor (siehe mein Beitrag Leistung eines Balkonkraftwerks mit Homematic IP erfassen).
Durch Konfigurationsänderungen musste ich diesen Zähler mehrmals außer Betrieb nehmen. Dabei wurde der Zähler immer wieder bei Null gestartet und entsprechend protokolliert. Hierdurch werden jetzt verschiedene Auswertungen verfälscht, die diesen Zeitraum betreffen.
Lösen kann ich das, wenn ich den alten Zählerstand als Offset auf die neuen Zählerstande addiere, sowohl für die historischen Daten als auch für die aktuelle Datenerfassung. Damit erzeuge ich wieder eine kontinuierliche Zeitreihe.
(Mittlerweile protokolliere ich übrigens nur noch die Differenzen von Zählerständen, so dass das Thema bei mir gar nicht mehr auftreten kann.)
Zeitpunkt und Offset herausfinden
Im ersten Schritt erstelle ich eine Abfrage im Data Explorer von influxdb 2.0, die die Daten für das betreffende Feld ermittelt. Dabei stelle ich die "AGGREGATE FUNCTION" auf "Custom" und deaktiviere alle Optionen. Die "WINDOW PERIOD" stelle ich ebenfalls auf "Custom", um die reinen Datenwerte zu erhalten. Das Ergebnis sieht wie folgt aus:
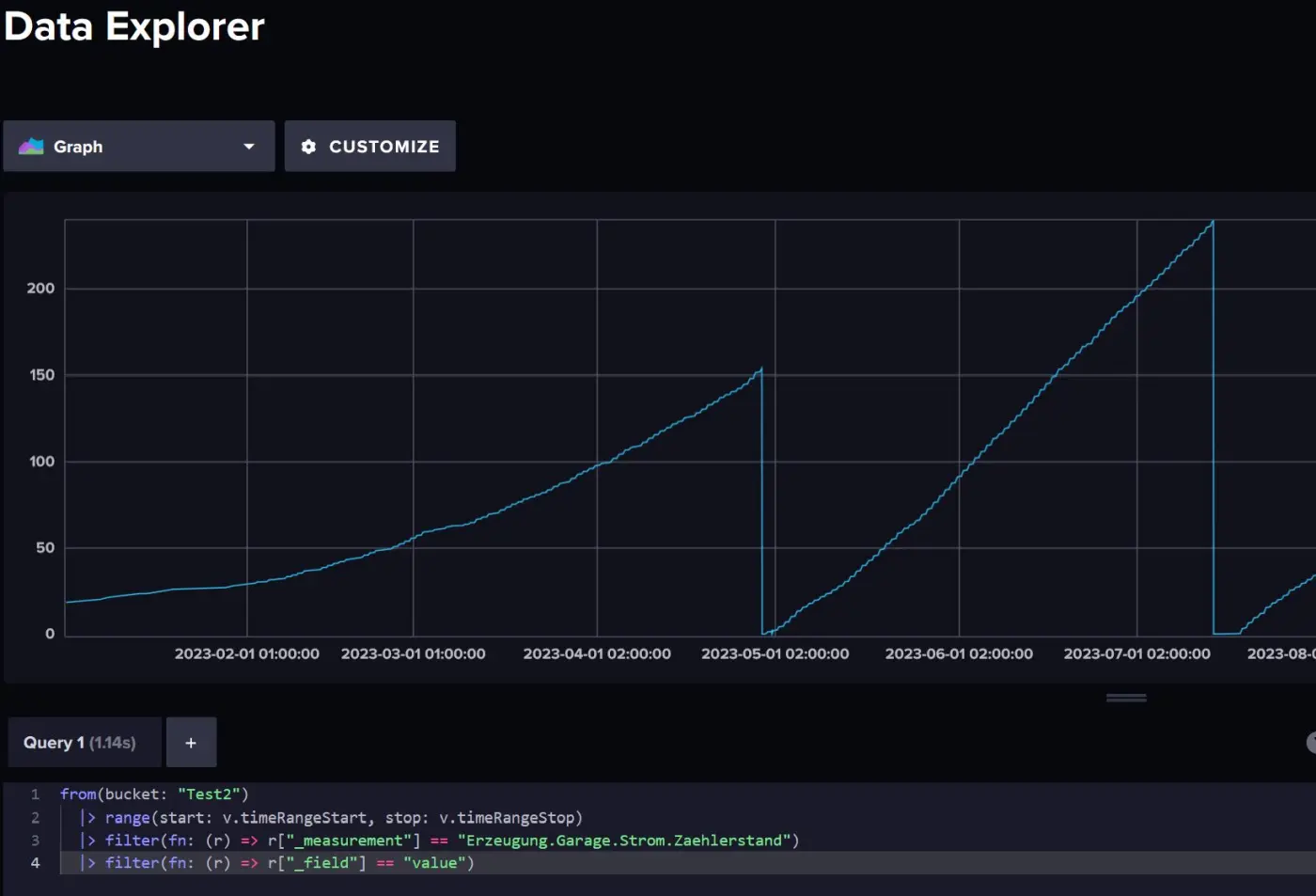
Nun finde ich den Datenwert heraus, bevor der Zähler auf Null umsprint. Dies kann man sehr schöne über den Data-Explorer interaktiv machen, wobei ich die "view raw data" Option hierzu wähle. Der für mich relevante Zeitpunkt ist "2023-04-28T17:41:59.477Z", den ich mir aus der Tabellensicht einfach kopiere. Der letzte Zählerstand zu diesem Zeitpunkt betrug "153.7812" KWh. Diesen Wert bezeichne ich als Offset, den ich für alle neuen Zählerstände addieren muss.
Wichtig: Für ein Funktionieren müssen die UTC-Werte ebenso wie die englischen Zahlen-Werte verwendet werden (mit einem Punkt für die Nachkommastellen).
Relevante Daten ermitteln
Jetzt muss ich alle Datensätze herausfinden, die nach dem betreffenden Zeitpunkt liegen, da ich dort die Werte ändern möchte. Hierzu ziehe ich von dem Datum, an dem der letzte "alte" Zählerstand erfasst wurde das jeweilige Datum jedes Datensatzes ab. Diese Differenz ist größer Null, wenn es sich um Datensätze vor dem betreffenden Zeitpunkt und kleiner Null, wenn es sich um Datensätze dahinter handelt.
Da influxdb keine Berechnungen auf Datumsformaten unterstützt, wandele ich diese Datumsangaben in Integer-Werte um und subtrahiere diese voneinander (im Prinzip ist das die Umwandlung der Datum/Zeitangaben in Nanosekunden im UNIX-Format).
Tipp: In der Flux-Dokumentation wird die Umwandlung in das uint-Format empfohlen. Dieses hat aber den Nachteil, dass es nur positive Werte bei einer Berechnung zulässt.
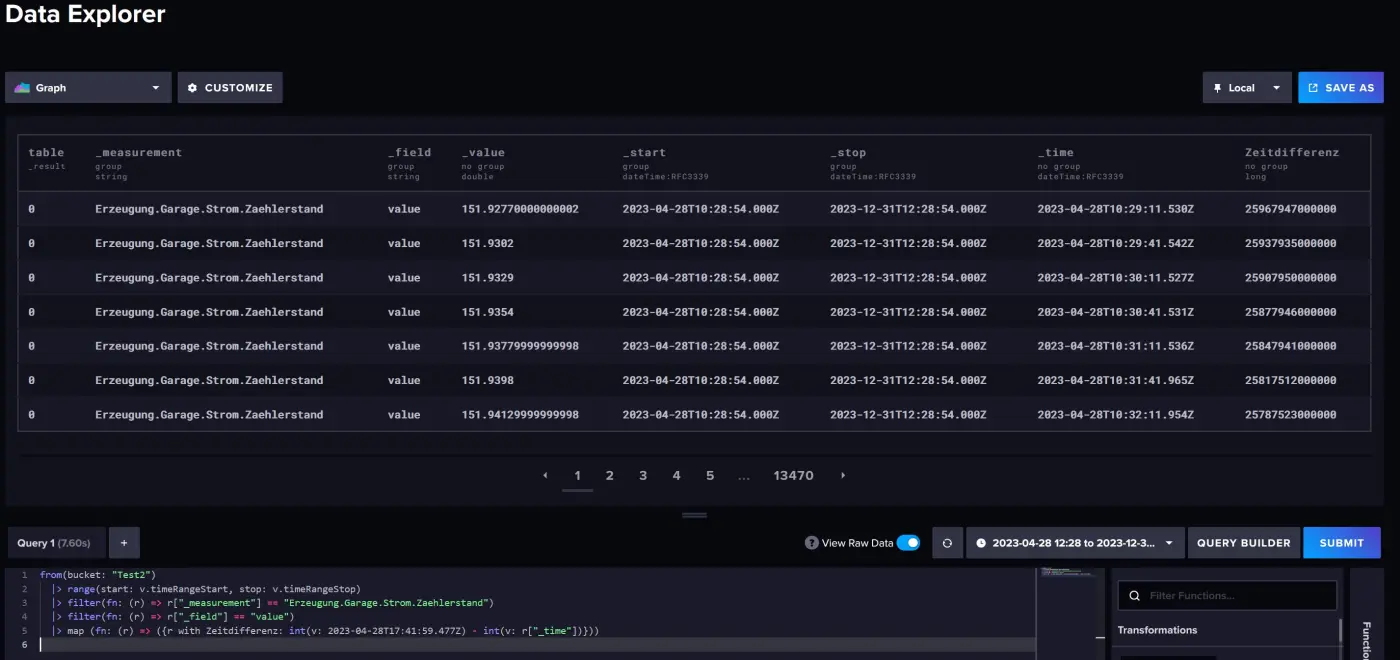
Diese Differenz speichere ich zur späteren Kontrolle in einem Feld zu jedem Datensatz ab, indem ich folgende Codezeile einfüge:
Im Data Explorer sieht das Ganze wie folgt aus:
Daten verändern und speichern
Für eine Anpassung habe ich jetzt alles zusammen. Ich addiere anschließend mit einer map()-Funktion für jeden Datensatz, bei dem die Zeitdifferenz kleiner oder gleich Null den Offset zum aktuellen Wert des Datensatzes für den Zähler.
ACHTUNG: Ich kann das zuvor erzeugte Feld "Zeitdifferenz" jetzt nicht nutzen, um die Wert einzusetzen, da die Pipe in Flux, die Werte tatsächlich erst nach einer Ausführung für den jeweiligen Datensatz verfügbar hat. Daher trage ich die Berechnung direkt in die map()-Funktion ein.
Der Code hierzu lautet:
Ein Testlauf sollte jetzt die richtigen neuen Werte ebenfalls als eigenes Feld anzeigen:

Ich empfehle, diese Änderungen so wie beschrieben zu kontrollieren und bei Bedarf Fehler zu korrigieren, damit nicht versehentlich auf den echten Daten falsche Werte geschrieben werden.
Sind alle Daten richtig, kann ich jetzt den Code so ändern, dass die Daten direkt in das _value-Feld der Datensätze geschrieben werden. Dazu ergänze ich ebenfalls noch die to()-Funktion, die die Daten final schreibt.
Der fertige Code für die Änderung sieht wie folgt aus:
Die Daten werden nun endgültig geschrieben.
Sofern es weitere Stellen gibt, die korrigiert werden müssen, kann man diese Korrekturen anschließend mit der gleichen Methode anpassen. Dabei muss mit jeder Datenkorrektur auch der Offset durch den neuen Offset erhöht werden.
Und wenn man weiter (wie in meinem Beispiel) Zählerstände in influxdb protokolliert, muss vor dem Speichern auf den jeweils aktuellen Zählerstand der letzte Offset addiert werden. Dabei empfehle ich, das Speichern neuer Zählerstände solange auszusetzen, bis die Datenkorrekturen abgeschlossen sind.
Hinterlasse einen Kommentar