Daten in InfluxDB verändern

Ich nutze zum Speichern von Daten die InfluxDB ab Version 2.x. Immer wieder passiert es, dass von einem der Sensoren ein falscher Wert oder im schlimmsten Fall ein ganzer Zeitraum mit falschen Werten geliefert und gespeichert wird. Um bei späteren Auswertungen z.B. mit Grafana keine komischen Grafiken zu erhalten möchte ich diese Werte korrigieren. Im folgenden Beitrag zeige ich, wie man das machen kann.
Fehlerhafte Daten identifizieren
Im ersten Schritt muss man herausfinden, wo die fehlerhaften Daten sind. Ich verwende hierzu die InfluxDB UI. Alternativ kann man das auch über Grafana machen.
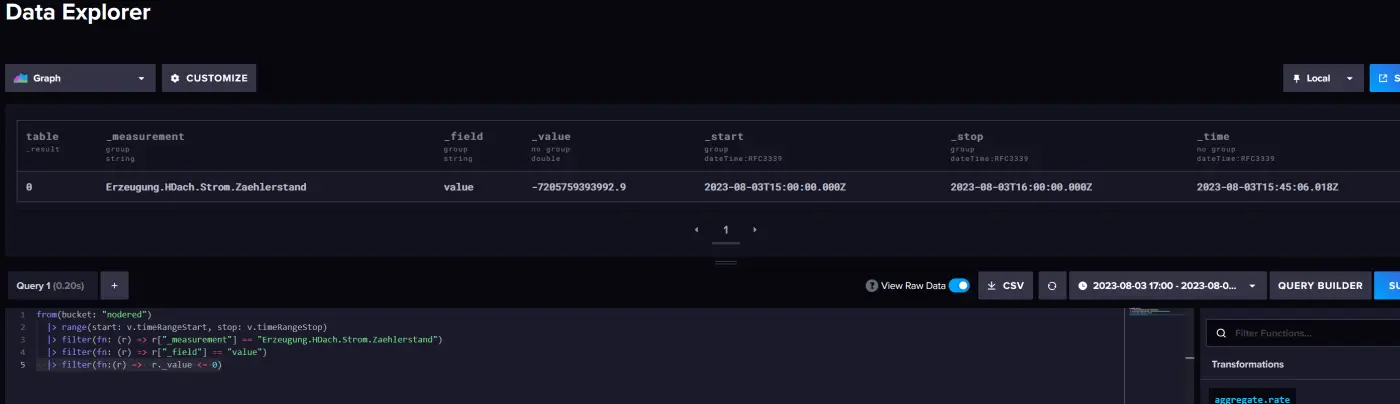
Dazu wähle ich im Data-Explorer für mein Bucket als erstes das Measurement und das Feld im Query Builder aus. Wichtig ist, dass man anschließend in den Script Editor wechselt und dort die Aggregate-Zeile löscht. Denn sonst erhält man aggregierte Werte über den voreingestellten Zeitraum.
In der anschließenden Grafik sieht man sehr deutlich Ausreißer, die man nun durch Klicken, Festhalten und Ziehen der linken Maustaste im Grafikfenster näher eingrenzen kann.
Durch Klicken auf den Zeitbereich und dort auf "Custom Time Range" kann man den Zeitraum dann exakt einstellen, der jetzt von Interesse ist.
Alternativ kann man auch einfach eine zusätzliche Filterfunktion angeben. In meinem Beispiel habe ich nach Werten gesucht die kleiner Null sind.
Das Script sieht dann beispielsweise wie folgt aus:
Nun schalte ich um auf die RAW-Data Ansicht und erhalte den Datenpunkt mit allen Details, der fehlerhaft ist.
Wert ändern
Wenn ich den Wert nur ändern möchte, dann nutze ich die Möglichkeit der InfluxDB-UI, Werte einfach überschreiben zu können.
Hierzu benötigt man
- den Namen des Measurements
- den Namen des Fields sowie den neuen Wert
- den exakten Timestamp im UNIX-Form mit Millisekunden (ich speichere alle Werte immer nur maximal mit Millisekunden ab).
All diese Daten sind verfügbar, einzig die Zeitangabe für den fehlerhaften Wert muss umgerechnet werden. Dazu verwendet man z.B, die Webseite https://it-tools.tech/date-converter. Mein falsche Zählerstand wurde am "2023-08-03T15:45:06.018Z" (_Time-Spalte) gespeichert. Umgerechnet ins UNIX-Format mit Millisekunden erhalte ich die Zahl "1691077506018" (bitte Timestamp Feld des Konverters mit den Millisekunden verwenden und nicht das Unix-Feld).
Nun geht man in der InfluxDB-UI auf den Menüpunkt "Load Data / Sources" und wählt dort "Line Protocol" aus. Hier wählt man den Bucket, in dem sich das Measurement befindet, anschließend die Option "Enter manually" und stellt die Zeitangabe auf "precision milliseconds" (wer hier andere Genauigkeiten verwendet, stellt das entsprechend anders ein und rehnet dann auch die Zeit mit anderen Genauigkeiten um).
Jetzt kann ich den folgenden Befehl eingeben, um die falsche Daten zu korrigieren und drücke anschließend "Write Data":
"Erzeugung.HDach.Strom.Zaehlerstand value=875.5 1691077506018"
Es sollte im Anschluss eine grüne Erfolgsmeldung erscheinen und der Wert in der InfluxDB für diesen Zeitstempel wurde den Wert 875.5 geändert
Wert löschen
Alternativ kann ich den Wert auch löschen. Dies geht beispielsweise mit dem curl-Befehl. Sofern man Windows nutzt, kann man das curl-Kommandozeilen-Tool über den Link https://curl.se/windows/ installieren. Der Befehl, um einenDatensatz mittels curl-Befehl zu löschen sieht wie folgt aus:
Alternativ kann man auch über die influxdb-Konsole einen Löschbefehl ausführen. Ich rufe z.B. in dem Docker Container, in dem influxdb läuft eine bash-Console auf und gebe einfach den folgenden Befehl ein:
influx delete --token --org --bucket nodered --start 2023-08-03T15:45:06.018Z --stop 2023-08-03T15:45:06.018Z --predicate '_measurement="Erzeugung.HDach.Strom.Zaehlerstand"'
In beiden Fällen würde der Eintrag aus der Datenbank gelöscht.
Ergebnis
Ich habe mittlerweile ganze Zeitreihen angepasst, in dem ich über Excel ganz viele Befehlszeilen generiert, in den Line-Protocol-Konsole geladen und anschließend ausgeführt habe. Die Vorgehensweise ist immer die gleiche, egal ob man einen oder mehrere Werte anpasst.
Hallo Dieter,
vielen Dank für die Anleitung. ich bekomme beim Update der Daten auch die „Erfolgreich“ Meldung in influx. Jedoch wird der Wert nicht aktualisiert. Hast du einen Tip?
Mein Line Protocol Befehl lautet: °C,entity_id=eg_flur_rauchmelder_air_temperature value=22 1698794043384
LG Gerrit
Hallo,
das „°“-Zeichen scheint kein valides Zeichen für einen Feldname im Line-Protocol zu sein. Wenn du dieses weglässt, dann funktioniert es. Leider habe ich in der InfluxDB Doku auf die Schnelle keine Informationen zu zulässigen Zeichen für Feldnamen gefunden. Überraschend ist, dass InfluxDB das Schreiben bestätigt und keinen Fehler ausgibt, obwohl nichts geschrieben wird.
Gruß
Dieter
Hallo Dieter,
vielen Dank für den Hinweis. Ich weis aber nicht wie ich es anders abfragen soll. Das Measurement lautet bei mir nunmal „°C“.
Ich hab auch einmal das Measurement weggelassen. Aber das funktioniert auch nicht. Hast du noch einen Tipp?
—–
from(bucket: „home_assistant“)
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) => r[„entity_id“] == „eg_flur_rauchmelder_air_temperature“)
|> filter(fn: (r) => r[„_field“] == „value“)
|> filter(fn: (r) => r[„_measurement“] == „°C“)
|> filter(fn: (r) => r[„domain“] == „sensor“)
—–
Grüße Gerrit
Hallo Gerrit,
ich kann leider nicht beurteilen, ob es sich um einen Bug im Line Editor handelt. Daher würde ich zuerst prüfen, ob ich die aktuelle InfluxDB Version habe und diese ggfs. updaten und das Ganze nochmal probieren.
Zusätzlich kannst Du auch Deine Frage im InfluxData Community Forum (erst anmelden) stellen, manchmal weiß jemand eine Antwort.
Wenn Du den Sensor kontrollieren kannst (wohin der schreibt), dann würde ich folgenden Workaround in Betracht ziehen: Kopiere alle Daten in ein neues Feld ohne Sonderzeichen (geht in Influx mit dem to-Befehl) und schreibe alle weiteren Daten vom Sensor in das neue Feld.
Gruß
Dieter
Hallo Dieter,
auch ich habe das Problem mit den Spikes. Danke für deine tolle Anleitung.
Auch ich habe mir ein Exceltool gemacht um die notwendigen Eingaben zu generieren. Mein großes Problem ist, dass ich nun schon fast nicht mehr zählbare Fehler habe und dies mit deiner beschriebenen Methode Tagelang dauern würde.
Ich suche die Details zu den falschen Daten mit einer Query im Explorer, lasse mir die Ergebnisse als Tabelle anzeigen und kopiere Seite für Seite in eine Exceltabelle – bei 15 Tabellen ok, bei mehr kaum mehr handhabbar. Früher gab es die Möglichkeit diese Tabelle in csv zu exportieren wurde aber in der aktuellen Version entfernt.
Also Problem 1: zu viel Fehler
Problem 2: wie bekomme ich die „richtigen“ Werte?
Grüße Otto
Hallo Otto,
Ich empfehle, die Export-Funktion von Grafana für größere Datenmengen zu nutzen. Du baust Dir dort deine Auswertung und speicherst sie in deinem Dashboard ab. Wenn du nun auf deinem Dashboard in der Auswertung oben rechts in der jeweiligen Ecke auf die drei Punkte gehst und anschließend Inspect und Data auswählst, kannst Du das Ganze mit den Button oben direkt in eine .csv-Datei exportieren. Diese Möglichkeit präferiere ich mittlerweile für größere Datenkorrekturen, weil man dann auch die Formatierungen bereits in Grafana anpassen kann.
Die falschen Werte kannst Du auf 0 setzen und anschließend löschen. Dazu würde ich diese nicht nur auf 0 setzen sondern auch den Zeitstempel auf ein eigenes Datum im letzten Jahrhundert ändern. Dann kannst du diese Werte anhand des Zeitstempels nachher recht einfach wiederfinden und löschen und sie sind aus deiner Zeitreihe raus.
Alternativ bietet sich an, die Werte auf den jeweiligen Nachfolger- oder Vorgänger-Wert zu setzen. Diese müsstest du aber vorher exakt bestimmen und dann entweder über eine zu bauende Query (stelle ich mir aufwendig vor) oder über Excel so aufbereiten, dass sie geschrieben werden können.
Gruß
Dieter
Hallo Dieter,
danke für deine schnelle Antwort.
Diese hat mir schon weitergeholfen, ich mußte nur mein Excel Tool anpassen um die andere Formatierung zu erhalten.
Bisher verwende ich die aufwändige Methode die vorigen „richtigen“ Werte zu suchen, was leider sehr Zeitintensiv ist.
Meine Antwort hat etwas gedauert weil ich stundenlang „Fehler“ korrigiert habe und in meinem Gesamtverbrauch immer noch die Anzeige auf 40.8 TWh steht.
Momentan habe ich das Problem, daß die Änderungen erst nach längerer Zeit „wirksam“ sind.
Bei der Suche danach bin ich nicht fündig geworden.
Bei den Suchen habe ich 2 gute Seiten gefunden:
https://hessburg.de/tasmota-smartmeter-faq/ Viele gut Links
und einen Tasmota SML Decoder
https://tasmota-sml-parser.dicp.net/
da mein Smartmeter mehr Infos über Knopfdruck ausgibt als in der jetzigen Ausgabeliste/Script.
Leider war dann doch nicht mehr Info herauszuholen.
Dann habe ich versucht die falschen Wert schon in Rode-Ned „Function“ abzufangen.
Leider habe ich dann keine Ausgabe des Parameters mehr – mehr testen erforderlich.
also Danke nochmals
Otto
Hallo Otto,
Ich entnehme deiner Beschreibung, dass noch immer zahlreiche falsche Werte geschrieben werden. Dies kann z.B. an einem falsch ausgerichteten Sensor liegen. Beim Infrarotsensor liegt es häufig daran, dass die LEDs nicht exakt übereinander liegen, so dass man durch leichtes Drehen schon eine Besserung erreichen kann.
Auf jeden Fall sollte man in Node-Red die Werte filtern, bevor man sie schreibt. Ausreißen kann man gut über einen Function-Node erwischen und den Wert z.B. auf 0 setzen. In einem anschließenden filer-Node kann man dann angeben, welche Werte überhaupt geschrieben werden solle und so Dopplungen oder Null-Werte verhindern.
Ich veröffentliche in den nächsten Tagen einen Beitrag, wie man ganze Zeitreihen einfach und direkt in Grafana anpassen kann. Evtl. findest du dann da auch noch Hinweise, die du vielleicht brauchen kannst.
Gruß
Dieter
Hallo Dieter, super was das alles machst….
Ich stehe da vor einem ungeschickten Problem, Haupt-Token gelöscht, sodass ein Influx Backup nicht mehr möglich ist, aber auslesen geht alles noch, nach Token Admin erstellung.
Frage: Wollte über influx line Protokoll Daten einspielen.
Sources -> Line Protocol -> Bucket (leerer Test Bucket erstellt ohne Begrenzung) ausgewählt und „Enter Manually“:
hoymiles,Value=157800 1701388800000
hoymiles,Value=198200 1704067200000
hoymiles,Value=250600 1706745600000
hoymiles,Value=381002 1709251200000
hoymiles,Value=445600 1711929600000
hoymiles,Value=488998 1714521600000
hoymiles,Value=474100 1717200000000
hoymiles,Value=584400 1719792000000
hoymiles,Value=655500 1722470400000
hoymiles,hoymiles Value=398800 1725148800000
hoymiles,hoymiles Value=317102 1727740800000
hoymiles,hoymiles Value=242898 1730419200000
hoymiles,hoymiles Value=94800 1733011200000
Influx fehlt da was, hab aber kein Plan was ich falsch mache. Mit der Anleitung von Influx, naja, hilft mir auch nicht weiter und weitere Stunden im Google sind auch nicht Ergebnisvoll verlaufen.
Vielleicht hat ja jemand einen Tipp?
Danke und schöne Freietage.
Gruss Tobi
Hallo Tobi,
Deine Zeitangaben haben jeweils eine Null zuviel. Diese muss 12stellig sein. Denke auch daran, im Line-Editor das Zeitformat (Precision) auch auf Millisekunden einzustellen.
Gruß
Dieter